


Прежде чем строить какую-либо модель по собранным данным, прогнозисту нужно понять, с чем именно он имеет дело и убедиться в том, что перед ним адекватный временной ряд, не содержащий ошибки. Для этого обычно используют графический анализ и / или статистический анализ данных.
Самое простое, что можно сделать прежде чем прибегать к каким-либо инструментам статистического или графического анализа — это просто посмотреть на имеющийся ряд данных в табличном виде. Беглый взгляд на данные позволяет понять, имеются ли в ряде выбивающиеся либо пропущенные значения, каким наблюдениям они соответствуют и есть ли в ряде данных какая-нибудь явная тенденция.
Если в распоряжении исследователя имеется малая выборка (с числом наблюдений, например, не более 20), содержащая 2 — 3 переменных, то провести такой элементарный анализ несложно. Однако проблемы начинаются, когда либо число наблюдений оказывается существенным, либо число переменных больше 3-х — глаза просто разбегаются от такого количества данных. А как быть, когда выборка содержит в себе высокочастотные данные (например, пятиминутные измерение потребления электроэнергии)?! В этом случае уже точно нужно обращаться к специальным статистическим инструментам.
Многие базовые статистические методы анализа рядов данных основываются на идеи упорядочивания ряда данных от меньшего значения к большему. Проведя такое упорядочивание можно сосчитать число наблюдений и рассчитать квантили распределения.
Квантиль — это значение, ниже которого лежит определённое число наблюдений, соответствующих выбранной частоте. Здесь и далее квантили мы будем обозначать как «\( q_{\alpha} \)», где \( \alpha \) — это выбранная частота. Например, \( q_{0.1} \) будет соответствовать тому значению ряда, ниже которого лежит 0.1 всей выборки.
С понятием квантиля плотно связано понятия «процентиль». Процентиль показывает процент наблюдений, лежащих ниже выбранного значения. То есть фактически если бы мы вместо \( \alpha = 0.1 \) использовали \( \alpha = 10% \), то мы получили бы десяти процентный процентиль, который был бы равен \( q_{0.1} \). Фактически разницы между квантилем и процентилем нет, всё упирается лишь в удобство обозначения и использования. Здесь и далее мы будем пользоваться названием «квантиль» даже в тех случаях, когда говорим о процентах от числа наблюдений (ибо не следует множить сущее сверх необходимого).
Квартили распределения — это квантили, кратные 25%, то есть соответствующие 25%, 50% и 75%. Их ещё иногда называют соответственно «первый», «второй» и «третий» либо "нижний", "средний" и "верхний". Обозначать мы их будем через «\( Q_1 \)», «\( Q_2 \)» и «\( Q_3 \)» соответственно.
Второй квартиль является самостоятельной полезной статистической величиной, так как показывает, что 50% наблюдений в выборке лежит ниже данного числа, а остальные — соответственно выше, то есть он фактически делит выборку пополам. Чаще в различной литературе его можно встретить под названием «медиана». Мы не будем отступать от этого обозначения.
Ещё две статистические характеристики, имеющие важное значение — это максимум и минимум переменной, которые фактически можно было бы назвать нулевым и единичным квантилями.
Ну и, конечно же, ни одно статистическо-аналитическое торжество не обходится без средней величины (которая на английском обычно называется «mean»), вычисляющейся по банальной и известной всем формуле:
\begin{equation} \label{eq:mean}
\bar {x} = \frac {1} {T} \sum_{t=1}^T x_t
\end{equation}
Эта же величина в математической статистике соответствует выборочному математическому ожиданию случайной величины, которое мы будем обозначать как «\( E(x) \)».
Достаточно часто в анализе можно ограничиться средней величиной и медианой, что, конечно же, не даёт всей той информации, которая иногда бывает необходима для адекватного анализа. Некоторые исследователи допускают ошибку и ограничиваются вообще только средней. Но это уже в корне неправильно, потому что средняя величина является эффективной характеристикой распределения только в случае с симметричным распределением случайной величины, типичным представителем которого является нормальной распределение:

Нормальное распределение
По этому графику видно, что медиана и средняя совпали. Но произошло это из-за пресловутой симметричности в распределении. Если же распределение несимметрично, то средняя величина оказывается сдвинутой ближе к длинному хвосту распределения. Например так:

Асимметричное распределение
На этом графике показаны вымышленные заработные платы вымышленного персонала в вымышленном вузе. По графику видно, что медиана оказалась ближе к пику распределения, чем средняя величина. Если делать выводы только на основе средней, то может сложиться впечатление, что средняя вымышленная заработная плата составляет порядка 1.75 вымышленных единиц (в.е.). Однако этот вывод будет некорректным, так как большая часть профессорско-преподавательского состава получает чуть меньше 1 в.е., при этом ректор и проректора получают значительно больше — от 8 до 10 в.е. Из-за их высокой зарплаты средняя заработная плата выглядит прилично. Медианная же заработная плата оказалась ближе к пику и составляет нечто в районе 1 в.е., что даёт нам как исследователям значительно больше информации о том, что твориться в вымышленном вузе на самом деле: 50% вымышленных сотрудников получает вымышленную заработную плату в размере ниже 1 в.е. А всё это из-за того, что медиана в меньшей степени подвержена влиянию выбросов, чем средняя величина (как говорят, она более робастная величина, чем средняя). Если бы мы рассчитали квартили этого распределения то могли бы получить информацию о том, что 25% всех вымышленных сотрудников получает меньше 0.5 в.е., а 75% - соответственно меньше 2 в.е.
Более точной оценкой пика распределения вообще-то является мода, которая показывает наиболее часто встречающееся значение в ряде данных, однако на практике использование её связано с различными трудностями. Обычно они вызваны тем, что мы очень часто имеем дело с непрерывными случайными величинами, а значит для оценки моды нужно идти на всякие ухищрения типа разбиения ряда на интервалы. Другая проблема, возникающая на практике, связана с таким явлением, как «мультимодальность». Оно выражается в наличии нескольких пиков в распределении. Выбрать корректный пик в этом случае — нетривиальная задача.
Итак, зная рассмотренные выше показатели мы уже можем одним взглядом объять всю выборку, имеющуюся в нашем распоряжении. Мы даже можем сделать вывод о симметричности распределения нашей переменной, сравнив медиану со средней. Однако это не даёт нам представлений о том, какими именно особенностями обладает выборка. Для того, чтобы понять, что к чему, нам нужно обратиться к момента распределения.
Моментом распределения называется величина, рассчитываемая по формуле:
\begin{equation} \label{eq:moment}
m_k = \frac {1} {T} \sum_{t=1}^T (x_t — c)^k,
\end{equation}
где \( c \) — некоторая константа, а \( k \) — это номер момента.
Если константа \( c \) равна нулю, то мы получаем начальные моменты распределения. Первый начальный момент распределения есть ни что иное, как математическое ожидание, что становится очевидно при сравнении формул \eqref{eq:mean} и \eqref{eq:moment}.
Когда \( c \) равна математическому ожиданию \( E(x) \), такой момент называют центральным:
\begin{equation} \label{eq:сmoment}
m_k = \frac {1} {T} \sum_{t=1}^T (x_t — E(x))^k.
\end{equation}
Обычно именно центральные моменты и представляют наибольший интерес, так как с помощью них можно оценить ряд характеристик распределения нашей случайной величины. Рассмотрим эти характеристики.
Первый центральный момент скучный и всегда равен нулю. Это следует из формул \eqref{eq:сmoment} и \eqref{eq:mean}. Зато центральные моменты других порядков несут значительно больше информации.
Одной из ключевых величин, основанных на центральном моменте, является дисперсия. Дисперсия — это второй центральный момент распределения. Она показывает меру колебаний случайной величины и рассчитывается (как следует из \eqref{eq:сmoment}) по следующей формуле:
\begin{equation} \label{eq:variancep}
m_2 = \frac {1} {T} \sum_{t=1}^T (x_t — E(x))^2.
\end{equation}
За счёт возведения отклонений от математического ожидания в квадрат происходит избавление от знаков, в результате чего получается значение, характеризующее средние отклонения слева и справа от математического ожидания. Чем выше дисперсия, тем выше разброс значений в ряде данных.
Если из дисперсии взять корень квадратный, то получится среднеквадратическое отклонение (ака «ско»):
\begin{equation} \label{eq:sigma}
\sigma = \sqrt{m_2}
\end{equation}
Несмотря на название, ско не является какой бы то ни было «средней» оценкой. Это со всей очевидностью следует из формул \eqref{eq:variancep} и \eqref{eq:sigma}: наблюдения в ско учитываются в форме «\( \frac{1} {\sqrt{T}} \)», а не «\( \frac{1} {T} \)», поэтому о каком-то усреднении говорить здесь не стоит.
На практике обычно дисперсия рассчитывается немного по другой формуле, а вызвано это тем, что в статистике есть доказательства того, что дисперсия, рассчитанная по формуле \eqref{eq:variancep} будет смещённой (в данном случае она будет занижена по сравнению с дисперсией в «генеральной совокупности»). Поэтому обычно вместо формул \eqref{eq:variancep} и \eqref{eq:sigma} рассчитывают формулы с поправкой на это смещение:
\begin{equation} \label{eq:variance}
V(x) = \frac{1} {T-1} \sum_{t=1}^T (x_t — E(x))^2
\end{equation}
и
\begin{equation} \label{eq:stdev}
s = \sqrt{V(x)}
\end{equation}
Величина \( s \) в таком случае уже называется «стандартным отклонением».
Обычно дисперсия и стандартное отклонение бывают нужны для построения доверительных интервалов, однако сделать каких-либо выводов о разбросе значений имея только их невозможно. Более-менее полезную информацию можно получить, рассчитав коэффициент вариации по следующей формуле:
\begin{equation} \label{eq:cv}
cv = \frac{s} {\bar x}
\end{equation}
Коэффициент вариации позволяет производить сравнение разброса значений в разных выборках, так как по сути приводит ско в разных выборках к безразмерным величинам. Однако по значению этого коэффициента делать какие-то выводы о том имеем ли мы дело с большим или малым разбросом всё так же некорректно. А всё потому, что этот коэффициент очень чувствителен к масштабу: если среднее значение показателя лежит близко к нулю, то, как следует из формулы \eqref{eq:cv}, коэффициент вариации будет принимать очень большие значения вне зависимости от того, какое получено ско.
Однако продолжим наше увлекательнейшее путешествие по моментам распределений.
Иногда центральные моменты стандартизируют. Делается это путём деления центрального момента на ско (или на стандартное отклонение в случае малых выборок):
\begin{equation} \label{eq:cstmoment}
m'_k = \frac{1} {T} \sum_{t=1}^T \left( \frac {x_t — E(x)} {s} \right)^k,
\end{equation}
что равноценно:
\begin{equation}
m'_k = \frac{1} {T} \sum_{t=1}^T \frac {(x_t — E(x))^k} {s^k},
\end{equation}
Нужно это обычно для избавления от масштаба случайной величины. Однако это так же позволяет получить интересную информацию об имеющемся распределении. А интересна она вот чем. В формуле \eqref{eq:cstmoment} фактически все значения разделяются на две группы: лежащие в пределах одного ско, и лежащие снаружи. Это лучше заметно, если взглянуть на следующие неравенства, характеризующие числитель \eqref{eq:cstmoment}:
\begin{equation}
\text{если } x_t — E(x) > s \text{, то } \frac {x_t — E(x)} {s} > 1.
\end{equation}
Что это нам даёт? Очень просто. После такой нормализации при возведении дроби в степень \( k \) эти две группы будут вести себя по-разному. Например, если \( k=4 \), то значения, лежащие в пределах одного ско будут существенно уменьшены и приближены к нулю. Так число 0.5 при возведении в 4-ю степень даёт 0.0625. В противоположность этому значения, лежащие дальше одного ско будут увеличены. Так число 2 в 4-й степени равно 16. То есть происходит ещё более серьёзное разделение выборки на две части. Если значений, лежащих за пределами одного ско, много, то они будут приводить к увеличению финального значение суммы в формуле \eqref{eq:cstmoment}.
Этот принцип используют два следующих полезных коэффициента.
Коэффициент асимметрии (skewness) — это ни что иное, как третий центральный стандартизированный момент. Рассчитывается он, как следует из \eqref{eq:cstmoment}, по формуле:
\begin{equation} \label{eq:skewness}
skewness = m'_3 = \frac {m_3} {s^3} = \frac{\frac{1} {T} \sum_{t=1}^T (x_t — E(x))^3} {s^3}.
\end{equation}
Из \eqref{eq:skewness} видно, что конкретные значения, лежащие слева и справа от математического ожидания не теряют свои знаки. Более того, они значительно увеличиваются в размере в случае, если лежат дальше одного ско. Поэтому, если слева от математического ожидания лежит какое-то очень большое значение (то есть оно отрицательное и велико по модулю), то возведение его в третью степень «потянет» коэффициент асимметрии в отрицательную сторону. Если в распределении таких отрицательных экстремальных величин несколько, но они встречаются редко (что характерно для распределений с длинным левым хвостом), то коэффициент асимметрии будет отрицательным. В противоположном случае коэффициент асимметрии будет положительным. Значения, лежащие в пределах одного ско нивелируют друг друга, поэтому коэффициент асимметрии показывает, какой из хвостов распределения длиннее.
У симметричных распределений коэффициент асимметрии равен нулю. Однако какие-то другие выводы кроме «положительный» или «отрицательный» по этому коэффициенту сделать нельзя — его величина ничем не ограничена и зависит лишь от того, как далеко от математического ожидания лежат те или иные значения.
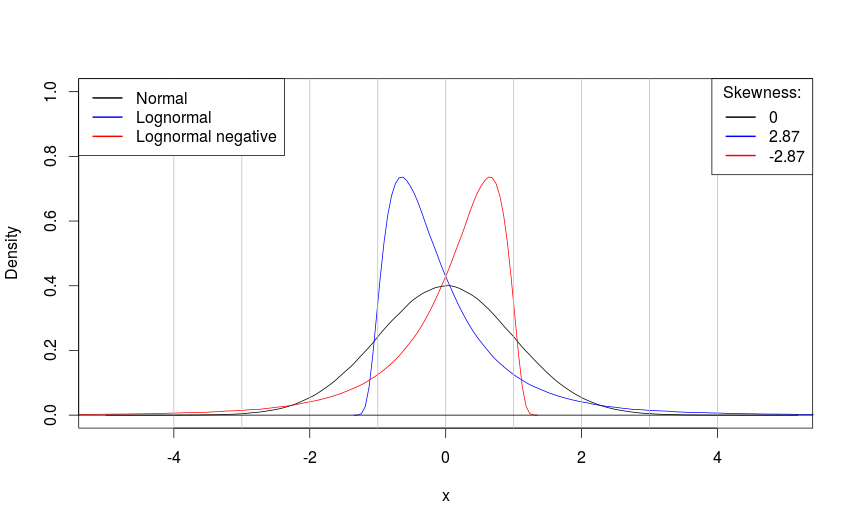
Распределения и их коэффициенты асимметрии
На рисунке выше показаны разные стандартизированные распределения случайных величин. Видно, как меняется значение коэффициента асимметрии в зависимости от длины одного из хвостов распределений.
Коэффициент эксцесса (kurtosis) — это четвёртый центральный стандартизированный момент. Он не так часто используется в анализе и несёт не так много информации, как предыдущие коэффициенты, но тем не менее обладает некоторой ценностью. Вот его формула:
\begin{equation} \label{eq:cstmoment4}
m'_4 = \frac {m_4} {s^4} = \frac{\frac{1} {T} \sum_{t=1}^T (x_t — E(x))^4} {s^4}.
\end{equation}
Смысл этого коэффициента мы фактически уже начали рассматривать ранее. Он является своеобразным показателем средней толщины хвостов распределения: большее значение коэффициента указывает на наличие большого числа величин, лежащих за пределами одного ско. Впрочем, он так же может просто указывать на наличие выбросов, потому что такие значения оказывают очень большое влияние на величину \eqref{eq:cstmoment4}. Однако это не всё. Обычно симметричные распределения так же характеризуются высотой пика вокруг математического ожидания. Из-за стандартизации в формуле \eqref{eq:cstmoment4} те распределения, у которых толстые хвосты ещё и характеризуются высоким пиком. Действительно, если к нормальному распределению добавить несколько выбросов, лежащих за пределами, например, 6 сигма с разных сторон, то ско, оценённое по формуле \eqref{eq:sigma} увеличится. Это за счёт увеличения знаменателя в \eqref{eq:cstmoment4} приведёт к тому, что число наблюдений, лежащих в пределах 1 ско вырастет, а значит и увеличится пик распределения (больше наблюдений будет лежать в пределах 1 ско). Это всё найдёт отражение в большей величине коэффициента эксцесса.
Коэффициент эксцесса на самом деле имеет наибольший смысл в случае с симметричными распределениями. В случае асимметрии он показывает ситуацию сродни «средней температуре по больнице»: толстые или же худые у распределения хвосты с обеих сторон в среднем.
В связи с тем, что коэффициент эксцесса ограничен только снизу (он не может быть отрицательным) и его тяжело интерпретировать, его обычно сравнивают с эксцессом нормального распределения, который равен трём. Поэтому формулу \eqref{eq:cstmoment4} обычно модифицируют следующим образом:
\begin{equation} \label{eq:kurtosis}
kurtosis = m'_4 - 3.
\end{equation}
В этом случае интерпретируется коэффициент так. Если он больше нуля, то у распределения имеются более толстые хвосты и больший пик, чем в нормальном распределении. Если же он меньше нуля, то мы имеем обратную ситуацию: более тонкие хвосты и меньший пик.

Распределения и их коэффициенты эксцесса
На рисунке выше показаны разные распределения и соответствующие им значения коэффициента эксцесса. Распределением с самыми толстыми хвостами на рисунке выше является распределение Лапласа. Видно, что чем выше пик распределения (по сравнению с нормальным), тем больше значение коэффициента.
Помимо рассмотренных нами здесь четырёх моментов распределения, существуют и моменты более высоких порядков, но практического применения в прогнозировании они не нашли.
Стоит заметить, что у моментов более высокого порядка есть свои явные недостатки: их значения подвержены влиянию выбросов (в случае появления экстраординарного значения в выборке, коэффициенты взлетают в небеса), а сами их значения ничем не ограничены, что приводит к затруднениям в интерпретации. Иногда для нивелирования первой проблемы используют другие коэффициенты, в основе которых уже не лежит возведение в целые степени.
Так вместо дисперсии для решения первой проблемы и получения более робастной оценки иногда используют среднее абсолютное отклонение (Mean Absolute Deviation, «MAD»):
\begin{equation} \label{eq:MAD}
MAD = \frac{1} {T} \sum_{t=1}^T \left| x_t — E(x) \right|
\end{equation}
В этом случае не происходит возведения в степень, а значит и наблюдения, лежащие на удалении от математического ожидания, не влияют на финальную оценку так сильно, как при расчёте дисперсии.
Иногда аббревиатурой «MAD» обозначают совершенно другой показатель — медианное абсолютное отклонение (при этом медиану в литературе по прогнозированию принято обозначать «Md», поэтому здесь мы такой показатель будем обозначать «MdAD»). Как следует из названия, эта величина ещё более робастна. Рассчитывается она по следующей формуле:
\begin{equation} \label{eq:MdAD}
MdAD = Md \left| x_t-Md(x) \right|
\end{equation}
Кроме того, в статистике существует доказательство того, что асимптотически относительно MdAD нормально распределённой случайной величины выполняется следующее условие:
\begin{equation}
\sigma = \frac{1}{\Phi^{-1}(3/4)} \cdot MdAD \approx 1.4826 \cdot MdAD .
\end{equation}
То есть эта величина связана с ско и может быть использована для его оценки в случае наличия выбросов в распределении.
Зная основы статистического анализа, можно получить много полезной информации об имеющихся данных. Однако имея в своём инвентаре ещё и графический анализ, можно творить аналитические чудеса!
Интересная статья, спасибо.
Спасибо,доступно и с примерами для проверки в R .
Я иногда использую online компилятор на сайте https://rextester.com/ ,базовые пакеты установлены и можно даже в телефоне попробовать ваши примеры.
Вопрос:есть продажи за 12 месяцев : 0.0.0.0.1.61.62.0.0.0.0.2.
Визуально бросается два выброса «61 и 62».
Таких «товаров» может быть 81000*35 строк, и нет возможности использовать R.
Только эксель с VBA.
Как можно предварительно оценить выборки на наличие выбросов ,а потом использовать IRQ?
Эксцесс не поможет,т.к. 61.62. расположены «рядом»
А прогонять все выборки через алгоритм «boxplot» в экселе займет много ресурсов.
Спасибо
Любопытно.
Один из вариантов (не идеальный, а скорее просто решение на коленке) — рассчитать MAD для каждого ряда, по нему — по формуле (17) ско. Затем построить 95% прогнозные интервалы по выборке на основе нормального распределения (с оценённым мат. ожиданием и ско), и смотреть, что вышло за границы. В таком методе очень много ограничений и неестественных допущений, но это быстрое решение проблемы.
Спасибо за быстрый ответ.
опечатка — в статье есть термин «кваРтиль» :)
но огромное спасибо за ваш труд
Здравствуйте, Ольга!
Спасибо за комментарий, но тут нет опечатки. Квартиль — это квантиль, кратный 25%. То есть это частный случай квантиля.