


В прогнозировании есть одна простая истина, к которой прогнозисты пришли достаточно давно: высокая точность аппроксимации данных не гарантирует высокую точность прогнозов. Это означает, что модель, дающая наименьшие ошибки по обучающей выборке, не обязательно даст такие же наименьшие ошибки по тестовой выборке. Противоположное («чем лучше аппроксимация, тем точнее прогноз») вообще возможно лишь для обратимых процессов, в которых никаких качественных изменений не происходит. Но, как мы знаем, в мире нет ничего более постоянного, чем перемены.
Впрочем, помимо этой простой истины есть ещё и другая: модель, заведомо плохо аппроксимирующая ряд данных, навряд ли даст точный прогноз. Это в свою очередь означает, что для получения более точных прогнозов, модель должна точно описывать ряд по внутренней выборке, быть адекватной поставленной задаче и включать все существенные переменные. Потому что, если модель представляет собой очень грубое и условное описание объекта, то по ней нельзя сделать адекватных выводов о самом объекте исследования.
Как видим, перед нами противоречие: модель должна хорошо описывать данные, но хорошее описание не гарантирует получения точных прогнозов. Противоречие решается достаточно легко, если следовать одному из базовых буддистский принципов — придерживаться срединного пути. Но как же найти эту середину? Для этого надо просто научиться оценивать качество построенной модели. А в этом нам помогут различные графики и ряд коэффициентов.
Графический анализ моделей
С графическим анализом всё просто. Все те инструменты, которые мы рассмотрели ранее в параграфе «Графический анализ данных«, сейчас нам пригодятся для того, чтобы понять, какая из моделей лучше и почему. Как всё это сделать в R мы так же уже рассматривали ранее, так что не будем тратить в этот раз время на примеры.
Самый простой метод оценки полученной модели — линейный график. На него достаточно нанести фактические значения, расчётные и прогнозные. Так мы сможем увидеть, как модель описала данные и насколько полученный прогноз соответствует сложившейся динамике. Более того, так можно понять (на основе знаний о прогнозируемом процессе), насколько полученные прогноз правдоподобен.
Очень простой пример с линейным графиком показан наследующем рисунке.

Линейный график по несезонной модели ETS(M,N,N)
На нём показан ряд фактических значений (чёрная сплошная линия «Series»), ряд расчётных (фиолетовая пунктирная линия «Fitted values»), точечный прогноз (синяя сплошная линия «Point forecast») и 95% прогнозный интервал («95% prediction interval»). Уже глядя на этот график можно сделать несколько выводов:
- Ряд фактических значений был описан моделью неплохо, хотя основные характеристики ряда выявлены не были — это видно потому что расчётные значения всё время как будто отстают от фактических на один шаг. К тому же, ряд расчётных значений не такой гладкий, как хотелось бы и в ряде наметились элементы сезонности (это особенно чётко видно с 1986 года) — каждый четвёртый квартал виден пик показателя. Это не криминал, но может говорить о том, что стоило бы обратиться к другой модели либо другому методу оценивания.
- Прогноз по нашей модели представляет собой прямую линию, параллельную оси абсцисс. Это хороший прогноз в случае, если ряд данных не имеет явной тенденции к росту либо снижению. Однако в нашем случае ряд данных явно демонстрирует увеличение показателя во времени. Поэтому такая тенденция в будущем хоть и возможна, но, скорее всего, не соответствует ожиданиям. Для того, чтобы здесь сделать какой-то однозначный вывод, нужно, конечно, понимать, с каким показателем мы имеем дело, и насколько реалистичен такой сценарий на практике.
- Прогнозные интервалы значительно расширяются и к последнему наблюдению составляют 5800 — 6500. Опять же, такие широкие интервалы — это не страшно, но одна из потенциальных причин этой ширины — неправильно выбранная (или специфицированная) модель. Так же на возможно неправильно выбранную модель указывает неровность прогнозного интервала при таком ровном прогнозе. Возможно, всё-таки надо было использовать другую модель (с трендом и сезонностью), а, может быть, мы не учли какие-то важные факторы.
На основе этих пунктов уже можно заключить, что стоит попробовать ещё какую-нибудь модель для прогнозирования этого ряда данных.
Если мы используем для выбора модели процедуру ретропрогноза, то на тот же самый график стоит нанести значения из проверочной выборки. Другая модель, построенная по тому же ряду данных, показана на рисунке ниже.
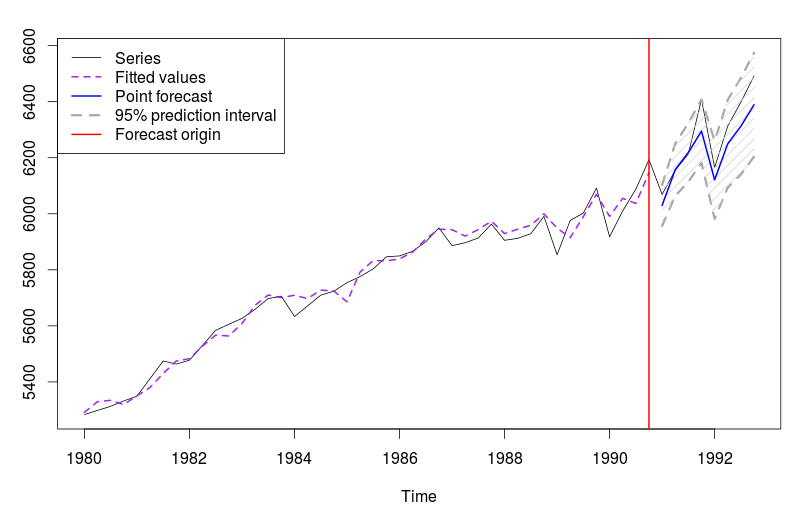
Линейный график по сезонной модели ETS(M,A,M)
По этому рисунку тоже можно сделать ряд выводов:
- Фактические значения описаны этой моделью лучше, чем предыдущей, но всё ещё есть ряд промежутков, аппроксимированных моделью не очень хорошо (как, например, наблюдение в начале 1984 года). Возможно, это говорит о том, что в это время происходили какие-то события, которые наша экстраполяционная модель не может уловить, а, может быть, нужно просто изменить метод оценки модели. При прогнозировании на практике стоит выяснить, что происходило в эти моменты, чтобы понять, носят ли эти события чисто случайный характер.
- Прогноз по модели получился с учётом сезонности, и, как видно по тестовой выборке, это сыграло модели на руку — она дала прогноз точнее, чем это сделала бы предыдущая модель ETS(M,N,N).
- Прогнозный интервал оказался уже, чем в предыдущем случае и по своей динамике соответствует поведению точечного прогноза (что говорит о том, что мы смогли уловить важные элементы ряда).
В общем, всё в этом графике указывает на то, что стоит обратиться к модели с трендом и сезонностью.
В ряде случаев по одному лишь линейному графику бывает сложно сделать выводы о качестве модели. Например, те же самые выбросы оценить по нему на глаз непросто. В этом случае нужно обратиться к графикам по остаткам модели. Даже простой линейный график по остаткам может дать много полезной информации.
Однако прежде чем приступать к непосредственному анализу, надо понять, что нам нужно. В идеальной модели остатки ни от чего не зависят, выглядят распределёнными случайно и желательно даже нормально. Графически это должно выражаться отсутствием какой-либо предсказуемости в остатках и ровными гистограммами и ящичковыми диаграммами.
На следующих рисунках приведены четыре графика по остаткам модели ETS(M,N,N) (той, которая соответствует первому графику в этой статье).
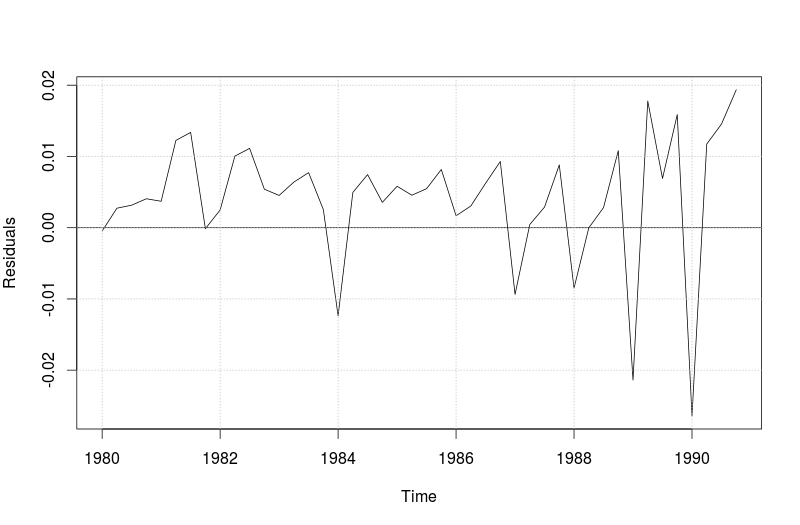 Линейный график по остаткам модели ETS(M,N,N)  Гистограмма по остаткам модели ETS(M,N,N)  Ящичковая диаграмма по остаткам модели ETS(M,N,N)  Точечная диаграмма по остаткам модели ETS(M,N,N) |
Взглянем критически на эти графики и попробуем вынести какую-нибудь полезную информацию.
- Линейный график по остаткам демонстрирует периодические колебания (которые особенно заметны примерно с 1986 года) — это всё из-за того, что мы не учли в модели сезонность. По остаткам она видна более явно, чем по графику по исходному ряду.
- Гистограмма по остаткам демонстрирует явную асимметрию: очень много ошибок лежит выше нуля (справа). Это так же указывает на неправильную спецификацию модели. Обычно исследователи при построении разных моделей стараются добиваться нормально распределённых остатков, но это требование на практике очень сложно удовлетворить. Именно поэтому нам нужно, чтобы они были хотя бы симметрично распределены относительно нуля. Это будет указывать на то, что модель построена без систематических ошибок.
- Ящичковая диаграмма показывает то же, что и гистограмма: мы имеем дело с асимметричным распределением. Помимо этого она ещё показала, что практически все отрицательные остатки можно статистически считать выбросами — то есть они настолько редко случаются, что играют небольшую роль в описательной способности модели. На себя так же обращает внимание завышенное среднее значение ошибки (красная точка по середине ящичка) — это так же сигнализирует о неправильной спецификации.
- Точечная диаграмма, построенная по расчётным значениям (Fitted) и абсолютным остаткам модели была построена для дополнительной информации. Она нам может показать, есть ли в модели гетероскедастичность. Другими словами, постоянна ли дисперсия остатков модели. Видно, что при меньших расчётных значениях остатки лежат в пределах от нуля до 0.015, в то время как при достижении 6000 по оси абсцисс разброс увеличивается. Это указывает на непостоянность дисперсии, что в свою очередь опять говорит о возможных проблемах модели.
Теперь рассмотрим точно такие же графики, но уже по модели с трендом и сезонностью.
 Линейный график по остаткам модели ETS(M,A,M)  Гистограмма по остаткам модели ETS(M,A,M)  Точечная диаграмма по остаткам модели ETS(M,A,M)  Ящичковая диаграмма по остаткам модели ETS(M,A,M) |
По ним можно заключить следующее:
- Линейный график демонстрирует более случайный характер распределения остатков, чем в предыдущем примере. Та самая пресловутая сезонность уже менее заметна. Но на себя обращают внимание три отрицательные ошибки, соответствующие 1984, 1989 и 1990 годам. Возможно, у таких ошибок есть какое-то объяснение. На практике стоило бы выяснить, что происходило в эти кварталы для того, чтобы улучшить описательные и прогнозные свойства модели.
- Гистограмма имеет более симметричный вид. Если бы не те несколько отрицательных ошибок, она бы выглядела вообще прекрасно.
- Ящичковая диаграмма так же демонстрирует большую симметрию относительно нуля (по сравнению с предыдущей моделью), а так же указывает на наличие нескольких выбросов. Это те самые отрицательные ошибки, которые мы отметили ранее. Всё-таки что-то с ними надо сделать!
- Последний график всё так же, как и в предыдущем примере указывает на наличие гетероскедастичности. Это значит, что при построении прогнозных интервалов сей неприятный эффект надо учесть, иначе интервалы могут оказаться либо слишком узкими, либо излишне широкими.
Как видим, на основе такого небольшого анализа можно получить много полезной информации об аппроксимационных свойствах модели и принять решение о том, что делать с моделью либо к какой модели обратиться.
Но помимо приведённых графиков есть ещё один, специализированный, который позволяет сравнивать распределение случайной величины с некоторым заданным. Называется он «квантиль-квантиль» потому что позволяет проводить поквантильное сравнение фактических и теоретических значений. Пример такого графика представлен на этом рисунке:

График квантиль-квантиль по остаткам
По нему видно, что наблюдения, находящиеся в хвостах распределения выбиваются и из-за них распределение остатков оказывается непохожим на нормальное. В идеале мы хотели бы, чтобы все точки на графике находились если не непосредственно на прямой линии, то хотя бы близко к ней, вокруг неё.
Коэффициенты для оценки качества моделей
Но, конечно же, одним графическим анализом ограничиваться не стоит. Очевидно, что глаз не всегда может увидеть то, что легко показал бы какой-нибудь коэффициент.
Первая группа коэффициентов, которые могут использоваться для оценки качества, обычно используется на остатках модели. Это все те статистические показатели, которые мы рассмотрели раньше в параграфе "Статистический анализ данных". Ничего нового и интересного относительно них сказать нельзя, поэтому здесь на них мы останавливаться не будем.
Добавим в нашу коллекцию два коэффициента, которые могут помочь при оценке описательной способности модели. Первый - это коэффициент корреляции, рассчитанный по фактическим и расчётным значениям. Чем ближе коэффициент к единице, тем в среднем ближе связь между этими значениями к линейной, то есть тем точнее описаны данные нашей моделью. Этот коэффициент мы уже обсуждали в параграфе "Выявление связей между переменными".
Второй полезный коэффициент - коэффициент детерминации. Он показывает процент объяснённой моделью дисперсии и рассчитывается по формуле:
\begin{equation} \label{eq:mq_Rsquared}
R^2 = 1 -\frac{SSE}{TSS} ,
\end{equation}
где \( SSE = \sum_{t=1}^T e_t^2 \) - это сумма квадратов ошибок модели (иногда обозначается ещё как RSS, SSR), \(TSS = \sum_{t=1}^T (y_t -\bar{y})^2\) - сумма квадратов отклонений фактических значений от средней величины. Здесь SSE соответствует ``Sum of Squared Errors'', RSS - ``Residuals Sum of Squares'', SSR - ``Sum of Squared Ressiduals'', TSS - ``Total Sum of Squares''. Все эти суммы квадратов на самом деле близки по смыслу к дисперсии остатков и дисперсии по исходному ряду данных. Просто в формуле \eqref{eq:mq_Rsquared} не происходит деление на число наблюдений.
Коэффициент детерминации более популярен в регрессионном анализе, нежели в других разделах прогнозирования, но может спокойно использоваться и при оценке экстраполяционных моделей. В случае, если модель идеально описывает ряд данных, SSE становится равной нулю, в результате чего \(R^2\) становится равен единице. Если же модель ряд совсем не описывает, а представляет собой просто прямую линию, то коэффициент детерминации становится равным нулю. В случаях с нелинейными моделями коэффициент может так же становиться отрицательным, но при этом неинтерпретируемым.
Несмотря на то, что коэффициент детерминации показывает этот самый процент той самой объяснённой дисперсии, сильно полагаться на него не стоит. Во-первых, он считается по обучающей части выборки, а значит просто показывает, насколько хорошо мы описали данные. При этом точность описания не гарантирует точность прогнозов. В некоторых случаях даже наоборот: излишне точное описание приводит к ухудшению прогнозных свойств модели (так как та начинает слишком сильно реагировать на шум). Простой пример - полиномы: чем выше степень полинома, тем выше \(R^2\), но тем обычно хуже точность прогнозов. Во-вторых, коэффициент детерминации будет всегда тем выше, чем выше число параметров в модели. То есть \(R^2\) у модели \(y = a_0 + a_1 x_1 + e\) будет всегда ниже, чем у модели \(y = a_0 + a_1 x_1 + a_2 x_2 + e\), даже если \(x_2\) в принципе ненужен. Именно поэтому иногда в эконометрике обращаются к так называемому скорректированному коэффициенту детерминации - \(R^2\)-adjusted. Но о нём мы поговорим в следующем параграфе.
В заключение по коэффициенту детерминации хотелось бы лишь добавить, что при построении моделей он не должен являться самоцелью: "Посмотрите, какая у меня хорошая модель получилась: \(R^2=0,936\)!" - типичная ошибка начинающих аналитиков. \(R^2\) может выступать лишь индикатором того, насколько модель адекватна. Низкие значения коэффциента детерминации могут указывать на то, что модель особого смысла не имеет, но при этом высокие значения не говорят о том, что перед нами хорошая модель.
По коэффициентам аппроксимации у меня всё. Но, если бы мы ограничивались лишь анализом аппроксимационных свойств моделей, то не было бы смысла вообще писать этот параграф. Нас, ведь, на самом деле больше интересует оценка точности прогнозов. Оценить её можно при использовании процедуры ретропрогноза. В этом случае наш интерес сдвигается с того, как модель себя повела на обучающей выборке на то, как она себя повела на тестовой. И здесь уже есть, куда развернуться.
Конечно, анализ этот можно проводить по аналогии с анализом обычной случайной величины, а значит и использовать весь стандартный набор коэффициентов, но в некоторых случаях стандартные методы просто неприменимы, а в других случаях не дадут полной информации о прогнозных свойствах моделей.
Например, коэффициент MAE, к которому мы обращались в параграфе "Простые методы оценки параметров моделей", будет в этом случае рассчитываться так:
\begin{equation} \label{eq:mq_MAE}
\text{MAE} = \frac{1}{h} \sum_{j=1}^h | e_{T+j} |,
\end{equation}
где \(e_{T+j}\) - ошибка на прогнозном шаге j, h - срок прогнозирования, T - номер последнего наблюдения в обучающей выборке.
У этого коэффициента есть два недостатка, которые проявляются только в случае анализа прогнозной точности моделей:
- Его значение сложно интерпретировать. Вот, допустим, получилось, что \(MAE = 1547.13\). О чём это говорит? Это много или мало? Если сравнить с другой моделью, то станет, конечно, ясно. Но какова будет реакция начальника, когда на вопрос прогнозисту: "Штурман, приборы?" - он услышит: "1547.13"?
- С помощью этого коэффициента можно проводить сравнение только между моделями по одному ряду данных. Но на практике часто стоит задача понять, как себя ведёт модель по нескольким рядам данных по сравнению с другими моделями. И тут уже полученные по разным рядам MAE складывать друг с другом нельзя, так как при сложении яблок с гвоздями получается абсурд.
Для того, чтобы так или иначе справиться с одной из или обеими этими проблемами, было разработано несколько коэффициентов.
MAPE - "Mean Absolute Percentage Error" - Средняя абсолютная процентная ошибка:
\begin{equation} \label{eq:mq_MAPE}
\text{MAPE} = \frac{1}{h} \sum_{j=1}^h \frac{| e_{T+j} |}{y_{T+j}},
\end{equation}
Это коэффициент, не имеющий размерности, с очень простой интерпретацией. Его можно измерять в долях или процентах. Если у вас получилось, например, что \(MAPE = 11.4\%\), то это говорит о том, что ошибка составила 11,4% от фактических значений. Этот коэффициент можно легко складывать по разным рядам. Можно даже рассчитать MAPE и изучить его распределение, используя инструменты статистического анализа. С другой стороны, можно отбросить в \eqref{eq:mq_MAPE} часть, отвечающую за "Mean":
\begin{equation} \label{eq:mq_APE}
\text{APE} = \frac{| e_{T+j} |}{y_{T+j}},
\end{equation}
и изучить распределение прогнозных ошибок на некоторый шаг j, используя всё те же статистические методы. Можно вместо "M", средней, посчитать "Md", медиану. Можно обратиться к квантилям... В общем, ни в чём себе не отказывайте, чувствуйте себя как дома!
Но, конечно же, без проблем быть не может. Из-за деления на фактические значения этот коэффициент оказался чувствительным к масштабу. Так, в случае, если \(y_{T+j}\) близко к нулю, то значение \eqref{eq:mq_APE} из-за деления на очень маленькое число взлетит. А уж если \(y_{T+j}=0\), то нас вообще ждёт бедствие вселенского масштаба.
Но на этом ещё не всё. Коэффициент по разному относится к положительным и отрицательным ошибкам. Допустим, что наш точечный прогноз на 137-м наблюдении составил \(\hat{y}_{137} = 20\), а фактическое значение при этом было \(y_{137}=10\). Какой будет ошибка APE в этом случае? Подставим эти значения в формулу \eqref{eq:mq_APE}, чтобы получить \(\frac{|10-20|}{10}=1=100\%\). А какой была бы ошибка, если бы фактическое значение было равно 30? Очевидно, что \(\frac{|30-20|}{30}=0,33(3)=33.(3)\%\). Вроде бы ошибка та же, но, по объективным причинам, она во втором случае составляет 33.3% от фактического значения, а не 100%. Получается, что этот коэффициент жестче относится к случаям завышенных прогнозов, чем заниженных. В случае с агрегированием прогнозов по разным значениям, это приводит к искажениям - прогнозист не получает достоверной информации о том, насколько его прогноз точен. Такая асимметрия не могла не привести к появлению других коэффициентов.
Один из вариантов решения проблемы предложили Spyros Makridakis и Michele Hibon, назвав коэффициент SMAPE - "Symmetric MAPE" - симметричная MAPE:
\begin{equation} \label{eq:mq_SMAPE}
\text{SMAPE} = \frac{1}{h} \sum_{j=1}^h \frac{2 | e_{T+j} |}{|y_{T+j}| + |\hat{y}_{T+j}|} .
\end{equation}
Число "2" в этой формуле не случайно. Дело в том, что в соответствии с первоначальной задумкой в знаменателе должно быть среднее между фактическим и расчётным значениями: \(\bar{y_t} = \frac{y_t + \hat{y}_t}{2} \). При подстановке этого значения в знаменатель, двойка переносится в числитель, поэтому мы и получаем то, что получаем.
Трактовка у коэффициента примерно такая же, как и у MAPE: какой процент составляет ошибка от этой самой величины \(\bar{y_t}\).
Идея, надо сказать, хорошая, но, конечно же, всё так же не лишена проблем. Коэффициент должен бы быть симметричным, но таковым до конца не является. Рассмотрим это на примере. Пусть наш прогноз на всё том же 137-м наблюдении составил \(\hat{y}_{137} = 110\), а фактическое значение было \(y_{137} = 100\). SMAPE в этом случае составит \(\frac{2 \cdot |100 - 110|}{100+110} = 9.52\%\). Если же прогноз оказался заниженным и составил \(\hat{y}_{137} = 90\), то SMAPE получится равным \(\frac{2 \cdot |100 - 90|}{100+90} = 10.53\%\). То есть, опять же, коэффициент демонстрирует смещение, только в этот раз в сторону завышенных прогнозов: завышенные прогнозы приводят к меньшей ошибке, чем заниженные. Сейчас уже в среде прогнозистов сложилось более-менее устойчивое понимание, что SMAPE на является хорошей ошибкой. Тут дело не только в завышении прогнозов, но ещё и в том, что наличие прогноза в знаменателе позволяет манипулировать результатами оценки. Кроме того, неясно, что именно минимизирует SMAPE. Поэтому я бы лично рекомендовал эту ошибку не использовать при оценки прогнозов (да, мы её активно использовали в нашем учебнике по прогнозированию, но сейчас я бы этого не стал делать).
Это, конечно же, не могло не привести к появлению ещё нескольких коэффициентов.
MASE расшифровывается как "Mean Absolute Scaled Error" и переводится как "Средняя абсолютная масштабированная ошибка". Предложена была Робом Хайндманом и Анной Коелер и рассчитывается так:
\begin{equation} \label{eq:mq_MASE}
\text{MASE} = \frac{T-1}{h} \frac{\sum_{j=1}^h | e_{T+j} |}{\sum_{t=2}^T |y_{t} - y_{t-1}|} .
\end{equation}
Обратите внимание, что в \eqref{eq:mq_MASE} мы имеем дело с двумя суммами: та, что в числителе, соответствует тестовой выборке, та, что в знаменателе - обучающей. Вторая фактически представляет собой среднюю абсолютную ошибку прогноза по методу Naive. Она же соответствует среднему абсолютному отклонению ряда в первых разностях. Эта величина, по сути, показывает, насколько обучающая выборка предсказуема. Она может быть равна нулю только в том случае, когда все значения в обучающей выборке равны друг другу, что соответствует отсутствию каких-либо изменений в ряде данных, ситуации на практике почти невозможной. Кроме того, если ряд имеет тендецию к росту либо снижению, его первые разности будут колебаться около некоторого фиксированного уровня. В результате этого по разным рядам с разной структурой, знаменатели будут более-менее сопоставимыми. Всё это, конечно же, является очевидными плюсами MASE, так как позволяет складывать разные значения по разным рядам и получать несмещённые оценки.
Но, конечно же, без минусов нельзя. Проблема MASE в том, что её тяжело интерпретировать. Например, \(MASE = 1.21\) ни о чём, по сути, не говорит. Это просто означает, что ошибка прогноза оказалась в 1.21 раза выше среднего абсолютного отклонения ряда в первых разностях, и ничего более. Показывать шефу эти цифры опасно для жизни аналитика.
Можно, конечно, знаменатель \eqref{eq:mq_MASE} заменить на простую среднюю по всему ряду, чтобы получить другую среднюю абсолютную масштабированную (относительно среднего уровня ряда) ошибку (sMAE - scaled MAE, иногда обозначается как MAE/mean). Для пущей безопасности в знаменателе можно взять среднее абсолютное значение ряда:
\begin{equation} \label{eq:mq_MASALE}
\text{sMAE} = \frac{T}{h} \frac{\sum_{j=1}^h | e_{T+j} |}{\sum_{t=1}^T |y_{t}|} .
\end{equation}
Модуль в знаменателе нужен для ситуаций, когда мы имеем дело как с положительными, так и отрицательными величинами, средняя величина по которым может быть близка к нулю. Если в такой ситуации брать просто среднюю, мы столкнёмся со всё той же проблемой масштаба. В общем случае значение \eqref{eq:mq_MASALE} будет показывать, какой процент от средней составляют ошибки прогноза. Эта величина всё так же будет несмещённой (по сравнению с MAPE и SMAPE), и может легко складываться с другими такими же величинами. Единственная проблема - тренд в ряде данных может влиять на итоговое значение \eqref{eq:mq_MASALE}. Но зато такой коэффициент легче интерпретировать, чем \eqref{eq:mq_MASE} - эта ошибка может легко измеряться в процентах.
Заметим, знаменатель sMAE может быть равен нулю только в одном случае - если все фактические значения в обучающей выборке оказались равны нулю. Такое возможно лишь в ситуациях с целочисленным спросом, если в распоряжении исследователя ещё не было ни одного ненулевого значения. В общем, очень экзотическая ситуация, в которой надо обращаться к нестатистическим методам прогнозирования. А так ошибка может использоваться как при прогнозировании положительных, так и отрицательных значений.
sMAE - практически идеальный показатель. У него есть лишь один небольшой недостаток - он никак не ограничен сверху. То есть теоретически возможны ситуации, когда \(sMAE = 1000\%\) (например, когда в проверочной выборке продажи неожиданно взлетели в разы, а в обучающей до этого составляли единицы), и с этим ничего не поделать. Такие ситуации, впрочем, тоже необычны, нечасто встречаются и будут приводить к похожим результатам во всех рассмотренных выше ошибках.
Ну, и не забываем о том, что вместо средней "M" в \eqref{eq:mq_MASE} и \eqref{eq:mq_MASALE} можно использовать и что-нибудь другое...
Но и даже на этом ещё не всё. Роберт Файлдс в 1992 году предложил нечто под названием "GMRAE" - "Geometric Mean Relative Absolute Error":
\begin{equation} \label{eq:mq_GMRAE}
\text{GMRAE} = \prod_{j=1}^h \left( \frac{| e_{a,T+j} |}{| e_{b,T+j} |} \right)^{\frac{1}{h}} ,
\end{equation}
где \(e_{b,T+j}\) - ошибка по некоторой второй модели.
GMRAE показывает, во сколько раз наша модель оказалась хуже (или лучше), чем выбранная для сравнения (модель-бенчмарк). Если \(GMRAE>1\), то наша модель оказалась менее точной, в противоположной ситуации - более точной. В качестве той самой второй модели для простоты можно выбрать Naive. Однако, можно и не ограничиваться Naive. Что именно выбрать обычно остаётся на совести прогнозиста, и в свою очередь может вызывать некоторые сложности. Действительно, почему именно Naive? Почему бы не модель экспоненциального сглаживания с демпфированным трендом или какая-нибудь ARIMA(2,1,3)?! Вопрос открытый. Но важно, чтобы по разным рядам происходило сравнение с одной и той же моделью.
Как видно, GMRAE легче интерпретировать, чем MASE, но сложнее, чем MAPE, SMAPE или sMAE. Впрочем, она всё так же не ограничена сверху и может теоретически достигать заоблачных величин.
Но без ложки дёгтя не обошлось. Из-за того, что эта ошибка представляет собой среднюю геометрическую, она не может использоваться в ситуациях, когда хотя бы одна из ошибок одной из моделей оказалась равной нулю - в этом случае GMRAE становится равной либо нулю, либо бесконечности.
Одна из модификаций этой ошибки - rMAE - Relative MAE (относительная MAE):
\begin{equation} \label{eq:mq_rMAE}
\text{rMAE} = \frac{\text{MAE}_a}{\text{MAE}_b} .
\end{equation}
Здесь мы фактически просто рассчитываем MAE двух моделей, и дальше делим одну величину на другую. Интерпретация получается похожей на интерпретацию GMRAE, но сама ошибка при этом оказывается более робастной (так как ситуация, когда MAE=0 оказывается значительно менее вероятной, чем ситуация, когда одна какая-то ошибка оказалась нулевой).
Последний коэффициент, который мы рассмотрим, призван оценивать не точность прогноза, а его смещение. Называется он "Mean Percentage Error" - средняя процентная ошибка:
\begin{equation} \label{eq:mq_MPE}
\text{MPE} = \frac{1}{h} \sum_{j=1}^h \frac{ e_{T+j} }{y_{T+j}}
\end{equation}
Можно заметить, что он похож на \eqref{eq:mq_MAPE}, но отличается лишь отсутствием модулей в числителе. Он показывает процент смещения прогноза. Положительные значения MPE указывают на систематическое занижение прогноза (то есть, мы недооценили спрос), а отрицательные - на завышения. Его значение так же, как и MAPE \eqref{eq:mq_MAPE} может измеряться в процентах. Он обладает теми же преимуществами и недостатками, что и MAPE.
На основе этой идеи со средними ошибками можно предложить и симметричную MPE, и среднюю масштабированную ошибку sME. Подробней на этом мы останавливаться не будем.
Ну, и совсем уж напоследок. Иногда в литературе встречается сравнение моделей на основе RMSE ("Root Mean Squared Error" - "Корня из средней квадратичной ошибки"):
\begin{equation} \label{eq:mq_RMSE}
\text{RMSE} = \sqrt{ \frac{1}{h} \sum_{j=1}^h { e_{T+j} }^2}
\end{equation}
Раньше бытовало мнение, что такое сравнение некорректно (см. Armstrong and Colopy, 1992), так как обычно приводит к выбору неправильной модели (то есть не самой точной). Всё из-за того, что эта ошибка сильно подвержена влиянию выбросов (из-за квадрата в формуле). Однако сейчас уже есть понимание, что проблема тут не в корректности и правильности, а в том, с чем именно мы имеем дело. Дело в том, что ошибки на основе MSE минимизируются с помощью средней величины, в то время как ошибки на основе MAE минимизируются медианами. Так что всё сводится к тому, что именно вы хотите увидеть.
Один из примеров эффективного использования ошибок на основе MSE - это прогнозирование прерывистого спроса. В этом случае число нулей в выборке может быть настолько большим (может легко перевалить за 50%), что все ошибки, основанные на модулях будут отдавать предпочтение нулевому прогнозу (мы ничего не продадим, поэтому нечего запасать - депрессивный прогноз). Это всё из-за того самого эффекта со средними и медианами (см. параграф методы оценки моделей).
На основе \eqref{eq:mq_RMSE} можно, например, предложить rRMSE:
\begin{equation} \label{eq:mq_rRMSE}
\text{rRMSE} = \frac{\text{RMSE}_a}{\text{RMSE}_b} ,
\end{equation}
которая может интерпретироваться аналогично rMAE.
На этом все самые популярные и полезные коэффициенты заканчиваются. В жизни встречаются, конечно же, и другие, но они обычно либо обладают большим количеством недостатков, либо значительно менее популярны среди прогнозистов.
library("smooth")
И посмотрим, как они работают на примере следующих двух моделей:
x <- es(M3$N1234$x,model="MNN",h=8)$forecast y <- es(M3$N1234$x,model="MAN",h=8)$forecast
Переменные x и y теперь содержат прогнозы на 8 наблюдений вперёд по моделям ETS(M,N,N) и ETS(M,A,N) по ряду N1234 базы M3-Competition.

Ряд N1234 и модель ETS(M,A,N)
График исходного ряда (см. выше) демонстрирует рост, и, откровенно говоря, модель ETS(M,A,N) выглядит на обучающей выборке неплохо. Она улавливает тенденцию к росту. Если не прибегать ни к какому фундаментальному анализу, то можно заключить, что возрастающий тренд - это то, что нас ждёт в ближайшем будущем. Но будущее таки не предопределено, именно об этом нам в очередной раз говорит следующий график, на котором показана модель ETS(M,N,N) и значения из проверочной выборки.

Ряд N1234 и модель ETS(M,N,N)
И именно поэтому прогнозирование всегда должно осуществляться параллельно с фундаментальным анализом.
Тем не менее, посмотрим, насколько точными оказались прогнозы по этим двум моделям. Для начала рассчитаем MPE:
MPE(M3$N1234$xx,x) [1] -0.009 MPE(M3$N1234$xx,y) [1] -0.037
Как видим, прогноз по второй модели оказался более смещённым - он составил -3,7%, по сравнению с -0,9% первой модели. Не удивительно - ситуация в проверочной выборке изменилась кардинально по сравнению с тем, что мы видели в обучающей!
Что же там с точностью прогнозов?
MAPE(M3$N1234$xx,x) [1] 0.009 MAPE(M3$N1234$xx,y) [1] 0.037
Из-за того, что прогнозы по обеим моделям оказались завышенными, значение MPE оказывается равным по модулю значению MAPE. Вторая модель ошиблась сильнее, чем первая.
Симметричная MAPE даст нам примерно то же самое:
SMAPE(M3$N1234$xx,x) [1] 0.009 SMAPE(M3$N1234$xx,y) [1] 0.036
Для MASE нам понадобится значение, по которому мы будем масштабировать ошибки. Рассмотрим классические вариант со средней абсолютной ошибкой в знаменателе:
MASE(M3$N1234$xx,x,mean(abs(diff(M3$N1234$x)))) [1] 1.218 MASE(M3$N1234$xx,y,mean(abs(diff(M3$N1234$x)))) [1] 4.820
Очевидно, что вторая модель ошиблась по сравнению с первой в четыре раза. Но, к сожалению, по MASE особо больше нечего сказать.
А теперь масштабируем её относительно среднего абсолютного уровня (sMAE):
MASE(M3$N1234$xx,x,mean(abs(M3$N1234$x))) [1] 0.011 MASE(M3$N1234$xx,y,mean(abs(M3$N1234$x))) [1] 0.043
Получили примерно ту же картину, только эти значения можно измерять в процентах и они несут чуть больше смысла.
Ну, и напоследок рассчитаем GMRAE. Для этого для сначала дадим прогноз по модели Naive, чтобы было, с чем сравнивать:
es(M3$N1234$x,model="ANN",persistence=1,h=8)$forecast->z
А теперь посчитаем GMRAE:
GMRAE(M3$N1234$xx,x,z) [1] 1 GMRAE(M3$N1234$xx,y,z) [1] 4.877
Первая модель, как видим, дала точно такой же прогноз, как и Naive - GMRAE оказалась равной единице. Вторая же модель спрогнозировала ряд в несколько раз хуже, чем это сделала Naive.
В этом нашем примере все ошибки дали примерно один и тот же результат. Однако на других рядах данных результаты могут различаться. Попробуйте, например, используя всё те же модели, сравнить прогнозы на следующем условном ряде данных:
example <- rnorm(100,2,1)